
Sommaire
Comprendre les enjeux de l’IA et de la protection des données personnelles est devenu une priorité pour toute organisation qui conçoit, entraîne ou exploite un système d’IA. Le sujet dépasse la seule conformité : il touche au traitement des données personnelles et au risque opérationnel, mais aussi, plus largement, aux droits fondamentaux. Une IA protection données mal encadrée expose directement l’organisation à des sanctions, à des usages non maîtrisés et à des violations de données à caractère personnel.
Le RGPD et l’IA : quelles obligations fondamentales s’appliquent ?
Le RGPD s’applique à tout traitement mis en œuvre par un système d’IA, quelle que soit la sophistication de l’outil ou la nature des technologies d’IA utilisées. Collecte, entraînement, ajustement, déploiement : chaque étape reste soumise au même cadre juridique qu’un traitement informatique classique. En pratique sur le terrain, la cybersécurité souveraine aide à articuler conformité, résilience et maîtrise des flux de données personnelles.

Les principes du RGPD face aux systèmes d’IA
L’IA et la protection des données reposent sur les principes posés par l’article 5 du RGPD. Ils structurent toute utilisation de l’intelligence artificielle dès lors que des données à caractère personnel, ou des informations présentant un caractère personnel, entrent dans le périmètre du traitement.
- Licéité, loyauté et transparence : chaque traitement doit reposer sur une base légale valable et rester intelligible pour les personnes concernées, y compris en cas de décision automatisée.
- Limitation des finalités : les données utilisées pour entraîner un modèle ne peuvent pas être réemployées pour des finalités incompatibles avec celles annoncées au départ.
- Exactitude : les données inexactes doivent pouvoir être corrigées, ce qui devient délicat lorsque le modèle absorbe de grands volumes hétérogènes.
- Intégrité et confidentialité : des mesures techniques et organisationnelles adaptées doivent protéger les données contre l’accès non autorisé, la perte ou l’altération.
La minimisation des données reste centrale. Seules les données nécessaires au traitement peuvent être collectées et conservées, ce qui entre souvent en tension avec des approches d’intelligence artificielle fondées sur l’accumulation massive d’informations.
Dans la même logique, la conservation doit être limitée dans le temps. Dès lors, il faut prévoir des durées de conservation claires et des mécanismes d’effacement, alors même qu’une donnée injectée dans un modèle peut devenir difficile à isoler ensuite. Le vrai levier de performance ici consiste à penser l’effacement, l’archivage et la traçabilité avant l’entraînement, pas après.
Minimisation des données et finalités dans les projets IA
La conformité RGPD de l’intelligence artificielle commence par une définition précise des finalités. La CNIL rappelle que l’intelligence artificielle peut être compatible avec la protection des données personnelles si les règles de minimisation des données, de réutilisation encadrée et de transparence sont appliquées dès la conception. À privilégier dès que la complexité monte : une cartographie documentée de chaque source, de sa base légale, de son usage prévu et du niveau de risque associé.
Le plan IA CNIL éclaire les conditions dans lesquelles le développement de technologies d’IA peut rester compatible avec les droits fondamentaux. En complément, l’organisation doit documenter l’origine des données, la finalité initiale, le fondement du traitement et la compatibilité du nouvel usage. L’arbitrage porte sur la performance du modèle d’un côté, les exigences de minimisation et de transparence de l’autre.
Souveraineté et localisation des données d’entraînement
L’hébergement, les transferts et la conservation des données à caractère personnel doivent aussi respecter le cadre juridique européen, faute de quoi le risque réglementaire augmente fortement. Une fois la sécurité posée, la question de la localisation devient déterminante pour la maîtrise réelle d’un système d’IA.
Lorsque des prestataires soumis à des lois extraterritoriales interviennent, la protection des données personnelles peut être fragilisée. Les jeux de données sensibles et les environnements d’entraînement gagnent donc à être hébergés dans l’Union européenne, avec des mesures de cybersécurité adaptées et une gouvernance claire des accès. Même logique qu’en architecture d’entreprise : la souveraineté technique réduit l’exposition du traitement et simplifie la démonstration de conformité.
La BigID protection IA permet précisément un déploiement confiné sur infrastructure européenne, hors juridictions étrangères soumises à des mécanismes d’extraterritorialité. Dès lors, le suivi des flux, la détection des écarts et l’application continue des mesures de protection deviennent plus fiables, y compris pour l’utilisation de l’intelligence artificielle dans des environnements réglementés.
Risques de l’IA sur la sécurité des données personnelles
Les systèmes d’IA amplifient des menaces déjà connues et en introduisent d’autres, plus difficiles à anticiper. Leur capacité à traiter de grands volumes de données personnelles en fait des cibles de choix, tandis que leur fonctionnement peu lisible complique la transparence et le respect des droits garantis par le RGPD.
Cybermenaces amplifiées par l’intelligence artificielle
En pratique sur le terrain, l’IA et la sécurité des données restent étroitement liées. Les mêmes technologies d’IA qui renforcent la cybersécurité servent aussi à industrialiser l’attaque : campagnes de phishing automatisées, messages très personnalisés à partir de profils publics, et malwares capables d’ajuster leur comportement face aux mesures de défense en temps réel.
Dès lors, les approches statiques montrent vite leurs limites. L’intelligence artificielle permet aux attaquants de contourner plus rapidement les filtres traditionnels, ce qui élève le risque sur la sécurité des données et impose des contrôles continus plutôt qu’une protection figée.
Biais algorithmiques et opacité des modèles IA
La transformation se joue sur un point souvent sous-estimé : les risques algorithmiques liés à la protection des données ne viennent pas seulement de l’extérieur. Ils naissent aussi dans les modèles eux-mêmes, dont l’opacité fragilise la transparence exigée par le RGPD et rend les décisions difficiles à expliquer, autant pour les personnes concernées que pour les autorités de contrôle.
- Biais d’entraînement : un modèle d’IA peut reproduire ou amplifier les biais présents dans ses jeux de données, avec à la clé des décisions inexactes ou discriminatoires, contraires aux exigences du RGPD.
- Droit à l’oubli compromis : une fois intégrées dans les paramètres d’un modèle, les données personnelles deviennent très difficiles à isoler puis à supprimer, ce qui complique l’exercice du droit à l’effacement prévu par l’article 17 du RGPD.
- Deepfakes et atteinte à l’image : les technologies d’IA permettent de produire des contenus falsifiés utilisables pour le chantage ou la désinformation, avec un impact direct sur les droits et libertés.
Auditer régulièrement les modèles, documenter les données d’entraînement et encadrer l’usage des données sensibles par des mesures de gouvernance claires permettent de limiter ces dérives silencieuses.
Centralisation des données et gestion des accès à risque
Le vrai levier de performance ici tient à la maîtrise des accès. Lorsqu’un système d’intelligence artificielle centralise des informations issues de plusieurs applications, il crée un point de concentration critique : en cas de compromission, le risque touche à la fois la cybersécurité, la sécurité des données et la protection des données sensibles.
Dès lors, la gestion des accès IAM permet de définir précisément qui peut interagir avec ces environnements, avec quels privilèges et sur quelles données personnelles.
En complément, une gestion imparfaite des droits ouvre la voie à des usages malveillants ou à des accès excessifs. Près de 80 % des brèches de cybersécurité impliquent des identifiants compromis ou des configurations défaillantes : à privilégier dès que la complexité monte, la traçabilité des actions, la révision des habilitations et la segmentation des accès réduisent nettement le risque lié aux technologies d’IA.
Rôle de la CNIL et cadre réglementaire IA en Europe
L’essor de l’intelligence artificielle a obligé les autorités européennes à faire évoluer leur cadre juridique. En France, la CNIL occupe une place centrale : elle adapte le RGPD aux usages d’IA, publie des repères opérationnels et contrôle les traitements de données les plus exposés en matière de risque, de transparence et de vie privée.
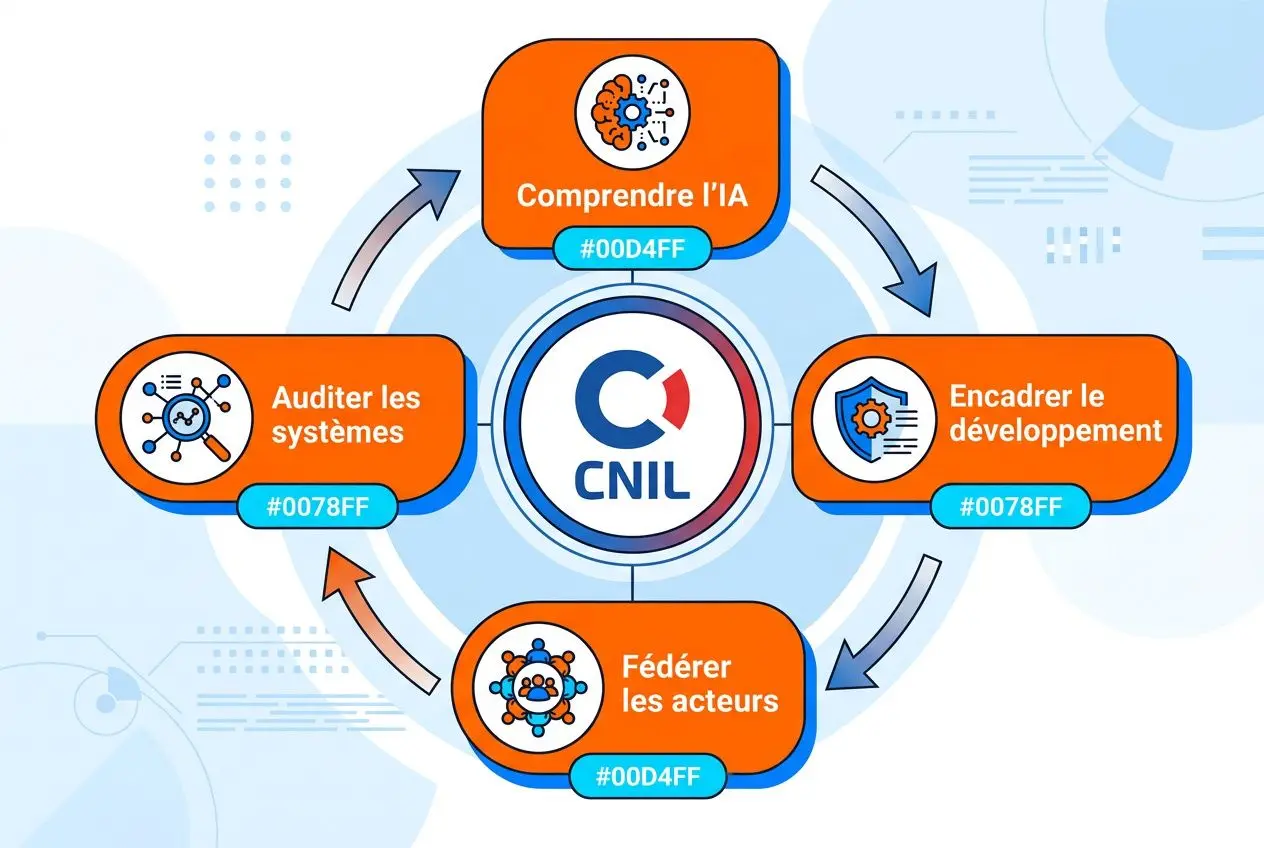
Actions de la CNIL pour encadrer l’IA et le RGPD
La CNIL considère que l’intelligence artificielle et la protection des données peuvent avancer ensemble, à condition d’encadrer le traitement dès la conception du système d’IA. En avril 2024, elle a publié sept fiches pratiques pour guider les acteurs sur le régime applicable, les finalités, les bases légales, la réutilisation, la conservation et la protection des données personnelles dès le design.
- Comprendre les impacts : un service dédié analyse les systèmes d’IA, leurs effets sur la vie privée, les biais possibles et les atteintes potentielles aux droits fondamentaux.
- Encadrer le développement : la CNIL précise les règles de minimisation, de partage, de conservation et de protection des données pour les phases d’entraînement, y compris pour l’IA générative avec des fiches en cours de publication.
- Fédérer les acteurs : l’autorité échange avec l’écosystème français et européen pour rapprocher innovation, cadre juridique et protection des données personnelles.
- Auditer les dispositifs : des contrôles ciblés portent sur l’information des personnes, les analyses d’impact, les mesures prises et l’exercice effectif des droits.
En pratique sur le terrain, ces fiches servent de base commune aux équipes produit, techniques, juridiques et conformité. Elles deviennent particulièrement utiles lorsque le système d’IA repose sur du scraping, sur de grands volumes de données à caractère personnel ou sur une possible mémorisation non voulue de données personnelles.
AIPD, droits des personnes et responsabilité des acteurs IA
La conformité IA selon la CNIL s’appuie d’abord sur l’AIPD, obligatoire lorsqu’un système d’IA présente un risque élevé pour les données à caractère personnel ou met en œuvre des traitements de données à grande échelle. Cette analyse documente le traitement, les finalités, les mesures de réduction du risque et la répartition des responsabilités entre les intervenants. Le vrai levier de performance ici tient à l’association précoce du DPO, afin que la protection des données ne reste pas théorique.
Dans la continuité, la chaîne de responsabilité doit être tracée sans zone grise. Fournisseurs de bases d’entraînement, développeurs, intégrateurs et utilisateurs doivent formaliser leurs rôles, notamment via des contrats conformes à l’article 28 du RGPD, car aucun acteur ne peut transférer ses obligations sans base contractuelle claire.
- Droit d’accès et portabilité : les responsables de traitement doivent permettre à chaque personne d’obtenir ses données personnelles et, lorsque le cadre s’y prête, de les transmettre à un autre service.
- Droit à l’effacement : protéger les données suppose des mécanismes techniques capables de traiter les demandes d’effacement, ce qui devient à privilégier dès que la complexité monte dans l’architecture du modèle.
- Information sur l’intervention de l’IA : toute personne concernée par un traitement automatisé doit recevoir une information intelligible sur l’utilisation de l’intelligence artificielle, sa logique générale et ses effets possibles.
Une fois la sécurité posée, un point reste sensible : la compatibilité entre les usages réels d’un modèle et les finalités annoncées lors de la collecte. La transformation se joue sur cette vérification continue, surtout pour les modèles généralistes susceptibles d’être redirigés vers des usages non prévus au départ, avec un impact direct sur la protection des données personnelles et la vie privée.
AI Act et RGPD : complémentarité du cadre européen
Le règlement européen sur l’IA, adopté le 3 juin 2024 sous le nom d’AI Act, complète le RGPD sans le remplacer. Le RGPD encadre tout traitement de données à caractère personnel; l’AI Act, lui, organise les obligations selon le niveau de risque des systèmes, notamment pour les usages à haut risque, la reconnaissance faciale, le profilage ou certaines formes de décision automatisée. Dès lors, l’intelligence artificielle et la protection des données relèvent d’un double cadre réglementaire, avec des exigences cumulatives.
Cette articulation impose une lecture à deux étages : conformité RGPD pour les traitements de données et conformité AI Act pour le système d’IA lui-même lorsqu’il entre dans une catégorie réglementée. En complément, le cadre juridique européen met l’accent sur la transparence, la robustesse, la supervision humaine et la documentation.
| Critère | RGPD | AI Act |
| Objet principal | Protection des données personnelles | Encadrement des systèmes d’IA par niveau de risque |
| Champ d’application | Tout traitement de données à caractère personnel | Systèmes d’IA déployés ou mis sur le marché en Europe |
| Obligations clés | Minimisation, finalité, droits des personnes, AIPD | Transparence, supervision humaine, documentation technique |
| Autorité de contrôle | CNIL et homologues européens (EDPB) | Autorités nationales de surveillance de l’IA |
| Entrée en vigueur | Mai 2018 | Juin 2024, application progressive jusqu’en 2027 |
Une approche structurée croise très tôt RGPD, AI Act, conformité CNIL et gouvernance interne pour sécuriser la conservation, la licéité des traitements de données, l’utilisation de l’intelligence artificielle et la protection des données personnelles.
Bonnes pratiques pour une IA conforme à la protection des données
Mettre un système d’IA en conformité ne se traite pas après coup. La transformation se joue sur l’intégration des exigences de protection des données dès la conception, avec une méthode progressive, des outils adaptés et une gouvernance claire des accès pour réduire chaque risque sans freiner l’usage métier.
Privacy by design et minimisation dans les projets IA
Le privacy by design appliqué à l’IA impose d’anticiper la conformité RGPD des systèmes d’IA avant la première ligne de code et avant toute collecte. En pratique sur le terrain, cela consiste à définir les finalités, à vérifier l’utilité réelle de chaque information et à concevoir l’architecture pour protéger d’emblée les données personnelles et les données sensibles.
Une fois ce socle établi, il devient plus simple de sécuriser les données personnelles, de limiter les usages secondaires mal cadrés et de démontrer la transparence attendue par le RGPD.
- Minimisation dès la conception : limitez les jeux d’entraînement au strict nécessaire, puis réévaluez régulièrement si le volume de données peut être réduit sans dégrader le système d’IA.
- Documentation des finalités : formalisez avant démarrage les usages autorisés, ainsi que les conditions dans lesquelles une réutilisation resterait compatible avec les finalités initiales.
- Anonymisation et données synthétiques : privilégiez ces approches lorsque les données réelles ne sont pas indispensables, afin de réduire l’exposition des données sensibles et de simplifier la démonstration de conformité.
- Révision périodique des droits : appliquez le moindre privilège pour que chaque personne ne conserve que les accès nécessaires à son rôle effectif.
En complément, la transparence doit être compréhensible au-delà des équipes techniques : logique générale du traitement, critères mobilisés, effets possibles sur les personnes concernées.
Outils de détection et classification des données sensibles
La conformité RGPD des systèmes d’IA ne peut pas reposer sur un contrôle annuel quand les flux deviennent massifs. BigID cartographie les données en quelques heures grâce à des milliers de modèles pré-entraînés, capables d’analyser plus de cent langues sur des formats structurés ou hétérogènes : une base solide pour identifier les données sensibles, suivre leurs mouvements et renforcer la protection des données dans le temps.
À l’inverse d’une photographie ponctuelle, cette lecture continue aide à repérer plus vite les écarts de traitement et les zones d’exposition. À privilégier dès que la complexité monte, l’outil détecte aussi la Shadow IA en temps réel, notamment les copilotes et modèles déployés sans validation formelle, qui créent un risque direct pour les données personnelles et la gouvernance du système d’IA.
L’analyseur de posture identifie les failles des agents conversationnels non autorisés, tandis que les restrictions d’accès limitent les requêtes anormales. BigID propose en complément une classification multilingue et brevetée sur les environnements cloud, SaaS et on-premise, ce qui permet de corriger les écarts plus tôt dans le cycle de traitement.
IAM, Zero Trust et souveraineté des données IA
Sécuriser les données personnelles dans un environnement IA suppose une gouvernance des identités aussi stricte que celle des jeux de données. L’IAM centralise le cycle de vie des comptes, contrôle les connexions au système d’IA et trace chaque accès avec horodatage précis. La MFA permet en parallèle de bloquer jusqu’à 99 % des attaques.
- Zero Trust appliqué à l’IA : aucune identité n’est jugée fiable par défaut, chaque tentative d’accès étant vérifiée pour réduire la surface d’attaque.
- PAM pour les comptes critiques : les comptes à privilèges restent minoritaires mais concentrent une part majeure des attaques abouties : la PAM en limite l’empreinte sur les ressources les plus exposées.
- Accès temporaires en contexte d’outsourcing : des droits éphémères, des sessions enregistrables et un périmètre restreint encadrent les interventions externes sans ouvrir l’ensemble des données sensibles.
- Déploiement souverain européen : BigID peut être installé sur une infrastructure strictement européenne, afin de maintenir les données hors des juridictions soumises au Cloud Act et d’aligner le dispositif avec le RGPD, NIS2 et DORA.
Une fois la sécurité posée, l’automatisation des droits réduit le délai d’attribution ou de révocation d’une semaine à quelques minutes. Dès lors, les comptes obsolètes disparaissent plus vite, l’audit devient plus fiable et la conformité RGPD des systèmes d’IA gagne en continuité, avec plus de cent cadres légaux embarqués nativement par BigID.
Foire aux questions
Comment le RGPD s’applique-t-il concrètement aux systèmes d’IA ?
Le RGPD s’applique à tout traitement des données personnelles effectué par un système d’IA. Il n’existe pas d’exception liée au seul caractère algorithmique de l’IA. En pratique sur le terrain, cela couvre l’ensemble du cycle : collecte, entraînement, inférence et interaction avec les utilisateurs.
Chaque traitement de données personnelles doit donc respecter les principes prévus par le cadre juridique européen : licéité, transparence, minimisation des données, exactitude, conservation limitée, confidentialité et protection des données. Dès lors, la protection des données personnelles ne se traite pas à part : elle structure les finalités du projet dès sa conception.
Le responsable de traitement demeure juridiquement responsable de bout en bout, y compris lorsque le système d’IA produit des décisions automatisées.
Quelles obligations concrètes s’imposent aux entreprises qui utilisent l’IA ?
Lorsqu’une IA repose sur des données personnelles, l’entreprise doit d’abord qualifier précisément le traitement, ses finalités et sa base légale. Une AIPD s’impose pour les usages à risque, notamment à grande échelle ou dans des contextes sensibles.
En complément, la désignation d’un DPO devient nécessaire lorsque la nature ou le volume du traitement de données personnelles l’exige. Il faut aussi informer clairement les personnes concernées, organiser l’exercice de leurs droits et documenter les choix de gouvernance pour démontrer la conformité au RGPD.
La logique de privacy by design reste à privilégier dès que la complexité monte. Elle conduit à intégrer les exigences de sécurité, de limitation de conservation et de confidentialité des flux dès la conception du projet.
Quel est le rôle de la CNIL face au développement de l’IA ?
La CNIL tient un rôle d’appui, de structuration et de contrôle. Elle publie des repères opérationnels, dont sept fiches de conformité consacrées à l’IA publiées en avril 2024, pour aider les acteurs à appliquer le cadre juridique aux usages concrets.
Elle favorise aussi le dialogue entre innovateurs et régulateurs, afin de faire évoluer les pratiques sans affaiblir la protection des données.
Enfin, la CNIL peut auditer un système d’IA déployé pour vérifier le respect des droits et du RGPD. Parmi ces chantiers, les modèles de fondation requièrent des précisions spécifiques sur la durée de conservation des données d’entraînement et les mécanismes d’effacement.


